Extracting data from financial documents with AI
05.04.2023, by iconicchain
How to process a big set of documents quickly, efficiently, securely and reliably? How to extract important data from each of the thousand invoices? Is there a way to manipulate values from financial records on the fly, without manually writing each of them into the database?
Similar questions have probably arisen in every auditor’s head and the same they did in ours, so we came up with iconicCompliance – a powerful tool that is itself the answer to all those questions. iconicCompliance has many remarkable ideas inside, united with the main one – to make auditor’s work faster and more efficient by automatizing many routine tasks and letting the specialist to stay creative and keep focused on really important things.
In iconicchain we believe that Machine Learning (ML) and Artificial Intelligence (AI) have potential in many industrial fields and compliance is not an exception. This post continues our series about how we revealed this potential while developing our product.
In previous posts we’ve already discussed the way we’ve chosen to deploy our ML models and described the main idea behind matching similar documents. Today we’re going to focus on the further step – extracting data from a document. The concept of document type mentioned in the post above was created to represent a simple yet powerful idea – documents of same types have similar layout. And the similarity of layouts leads us to the next idea of having an adjusted template for each document type with selected areas from which we want to extract data for every new document of the same type. We call these areas “fields” and divide them into two main groups – static and dynamic. Static fields are expected to stay in the relatively same position for every new document and dynamic fields can move significantly. Examples of static fields may be a company name, or any other information on the header of the document. A good example of a dynamic field is a table. Different documents of the same type may contain tables with different numbers of items and therefore different lengths. To extract data from a new document of a certain type, the template with adjusted fields for that document type is required. Here is the moment where AI starts to help us.
Getting insights
Document type may contain any number of fields, both static and dynamic. Manual adjustment of document types may take a lot of time, when dealing with large quantities of different kinds of documents. We came up with a helpful ML model that suggests the user coordinates of relevant fields. In other words, this model draws rectangles in the user interface (UI) and the user has only to decide if they agree with suggestions. To create this model, we used YOLO architecture that was trained to detect around 15 types of fields. A custom dataset with labeled fields was created for that purpose.
The user has full control over suggestions. To make the model work, the user has first to adjust fields that they want to get suggestions for. For example, if one wants to detect the “Date” field on the document, they should attach the “Date” field to the corresponding ML type and after that they would get suggestions for “Date”. Same works for other fields as well. In case there are multiple fields matching with the same ML type in the document, a language model is used to find the best match based on other neighboring content or labels, eg. “Delivery Address” vs “Home Address”. The feature is aimed to cut out user interference and to highlight important parts of documents. An example of the suggestions in the UI could be seen on figure 1.

Figure 1. An example of field suggestions in the UI
Parsing the document
After the user has adjusted all fields on the document template either by themself or by using insights from AI, new documents of the same type can be processed to extract information from them. Static fields are parsed according to their coordinates on the doctype (template), and dynamic ones are sent to the separate pipeline. We track font size and style inside every static field to be able to merge data if it extends outside the field a bit or if the field shifts slightly.
To “read” data from an image, optical character recognition (OCR) techniques are used. OCR is a process of conversion of images of typed, handwritten or printed text into machine-encoded text. It is a common method of digitizing printed texts so that they can be electronically edited, searched, stored more compactly, displayed on-line, and used in machine processes.
The next step is aimed to parse information from non-static parts of a document. The best example of such dynamic fields is data stored in tabular format. Different documents of the same type may contain tables of different lengths and therefore different numbers of items. A simple example of that case is shown in Figure 2.
Figure 2. A simple example of a dynamic field problem
The typical workflow for this problem usually consists of three steps:
- Detect the table coordinates on the image
- Extract table structure (columns, rows, headers, etc.) and define cells as a crossing of rows and columns
- Apply optical character recognition (OCR) on each cell to convert data from an image of text into a machine-readable text format.
We’ve adapted this workflow to meet our needs. The overall idea was to use the results of a document matching algorithm that allows us to assign every new document to its corresponding type. We assume that documents of the same type have a similar layout and in case there are some tables on the “base” document that defines doctype, we expect all new documents of this type to either contain tables of similar structure or not contain tables at all.
The main purpose of this assumption is to help us to define some templates on the doctype image and then search for these templates on a new image of the same type. Then these templates are used as “anchors” to help us better understand the layout of the document.
We considered detection of a table as a CV (computer vision) object detection task and decided to use the YOLO model. YOLO (You Only Look Once) is a powerful transformer-based object detection NN (neural net) that could be applied to many real-life problems and scenarios. The variety of different YOLO models allows us to keep balance between power of the model and its size. The model was trained on our custom dataset of documents. Figure 3 below shows an example of detecting a table. When the table is detected, we apply corrections to YOLO’s prediction by “anchors” that we’ve found on the new document.
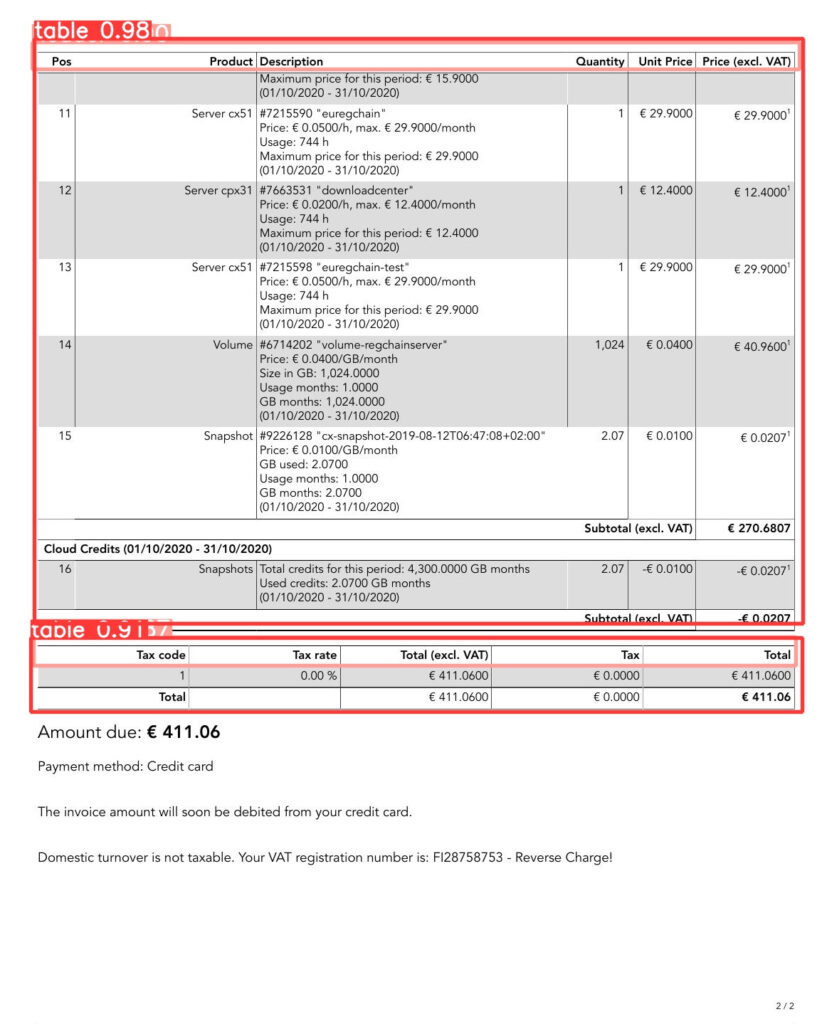
Figure 3. Detected tables
After we’ve detected the table, another NN model comes into the game to extract the table structure. This is also an object detection task as we need to find rows on the image of a table. For that purpose, we use the DETR model, trained to detect the layout of a table. DETR can detect rows, columns, headers, footers, and some other table structures. An example of the performance of DETR could be seen in figure 4.
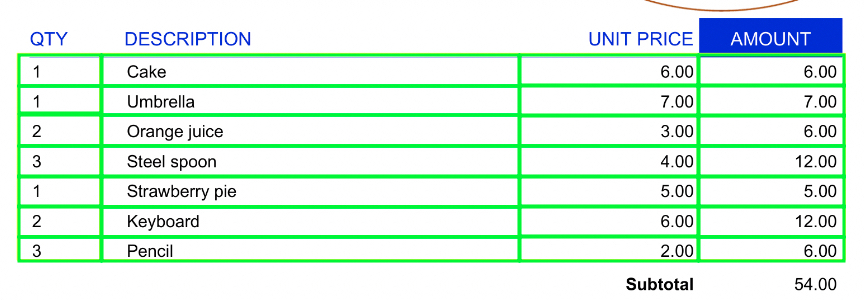
Figure 4. Extracting table structure
Now it’s time to proceed to the final step of the dynamic fields pipeline – apply OCR on each cell and write extracted data to the database. We have integrated PyTesseract directly and independently into our pipeline as our Optical Character Recognition (OCR) tool. After all these steps the data from the document is stored in the database and is ready for further processing.
Processing documents is a vitally important part of the auditor’s work, and our goal is to make it easier and faster. We’re continuously working on improving our pipelines, so keep an open eye on our website to get the latest news and updates.