Powering Compliance Applications through Machine Learning
Md Raisul Kibria, Friday, October 7, 2022
With the advent of Machine Learning (ML) and data-driven algorithms, we are observing Artificial Intelligence (AI) do things that were virtually unimaginable otherwise. It’s not only the fun things like art or melody generation that are possible but now AI-based services are being integrated into everyday tasks and activities to make them much easier and more efficient. Analyzing and proving compliance are no exception.
Generally, the bulk of the data generated and communicated in businesses are in unstructured binary format which, even though can be produced relatively easily, is not easy to process or analyze. As a result, extracting structured information from these data for processing and storing in databases has been a very important business problem for a while. One such greatly affected profession is the Auditors who go through financial records to evaluate the credibility of accounts and compliance with governance and tax laws. As most financial purchases and sales are acknowledged with a receipt or invoice either provided as a piece of paper or a digital document, an auditor has to maintain these records in a structure that supports CRUD (create, read, update and delete) operations and any queries in the future.
iconicchain’s new rule-based Document Parsing engine is a semi-automated system for extracting structured information from a wide variety of documents, e.g.- financial records, common business documents, or even photo IDs. The system is designed with a human-in-the-loop so that the user has full control over how the information is extracted. We aim to combine rule-based field annotations and ML-based classification to limit manual effort by users to just a few examples. The core of the system is ML models that can identify the class (layout) of an input document for finding which set of user-defined rules are applicable. While designing these ML services, we had to address two different challenges – first to design predictive algorithms that are accurate with low false-positive rates, and then to make these ML services production-ready in the most effective, efficient, and sustainable way. Our approach to the first part is described in this post [Farkhad’s post link] and here, I am going to discuss how we developed APIs to serve the ML model predictions and enabled continuous training for the models.
Integrating as a Sustainable System
The first step in deployment was to integrate the experimental ML models into the existing stack so that other parts of the system could access and provide services based on them. As we aim at the most reliable, flexible, fast, and efficient products at the company for our clients, the ML development team decided to use open-source technologies to build custom but powerful APIs to serve the models.
After a careful evaluation, we selected TorchServe for the deployment of our ML models and handled the arising compatibility issues by translating all our models to the PyTorch framework. TorchServe is both intuitive and fast, and it provides separate built-in APIs for Management and Metric logging. How the prediction outputs are served via the inference API is highly customizable through the use of a handler module. One of its usages was in combining the image processing task directly with the output from the segmentation model used for background removal.
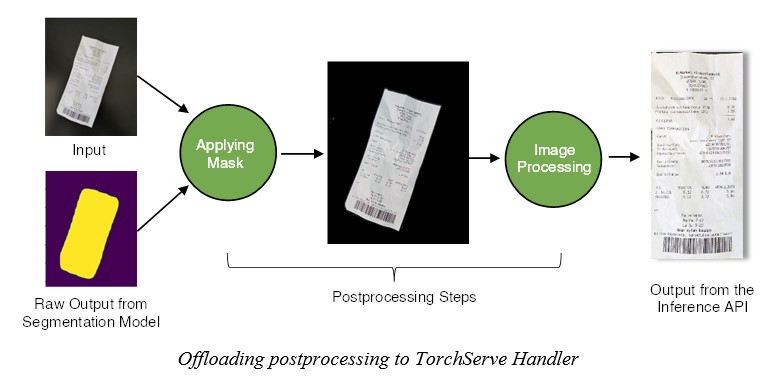
The ML container was packaged separately with only the ML-based requirements. To make it lighter weight, we removed the GPU support completely, so only the users owning a GPU could have a separate system, whereas the others can use the CPU implementation. As a result of combining our lightweight models with the TorchServe server, the response time on even CPUs was very fast. Every component and the APIs were also designed to be sustainable, so maintenance costs are minimal.
Adding Continuous Training Support
As the user continuously labels new or unclassified samples, we get several labeled examples representative of the target distribution. Hence, these examples can be used to improve the document type recognition model through a continuous training API.
As TorchServe does not provide a retraining workflow, we designed a custom API using Flask with support for the retraining loop. The default parameters are read from a static file which can be overridden by passing them through the API. Aiming for this process to be self-monitored, a separate validation set of data is included so that the benchmarks are universal. This benchmarking dataset is used to define a common objective for deciding whether the retrained model is better than the earlier versions. The data is passed to the retraining endpoint via special data objects that point to files in a volume shared by containers of the main application and the ML container.
We are constantly working to improve our MLOps platform – keep an open eye on our website for more updates.