Automating Financial Document Type Recognition
Farkhad Kuanyshkereyev, Friday, October 28, 2022
Many organizations and companies today perform a lot of work related to manual data extraction from printed documents. Those documents could be invoices, receipts, checks, bills, etc. Numerous hours are spent by auditors to capture certain information such as the items purchased, their prices, the address of the vendor, total cost, and so on. Moreover, some of the data needs to be checked against the existing information in databases. Other kinds of data need to be inserted into electronic tables. Organizations can benefit from the automated data extraction solution from document images. The topic is ongoing research in the field of machine learning, computer vision, and artificial intelligence. This blog post will provide information about the first part of the potential solution to the problem.
The challenge
Whenever an auditor is processing documents, he/she is searching for values of certain fields (keys). Those fields could be name, surname, address, item list, total price, etc. The set of fields might vary from document to document. Therefore, it is possible to identify similar patterns in certain documents that have the same layout and a set of defined fields. Figure 1 demonstrates two documents that belong to the same document type.

Documents that belong to the same document type will have the same set of fields and their positions will relatively be the same. Thus, it is possible to reduce the search space of potential fields to the given document type. The task becomes to identify the document type of a given document image.
It is challenging to define heuristics for identifying similar document types, thus the machine learning approach is used. The machine learning approach requires a good amount of data. Moreover, the number of document types needs to be big enough for the machine learning algorithm to work properly. Therefore, the dataset size was increased artificially. The first technique used is data augmentation. The set of existing documents was reused with different image processing techniques such as enhancement of brightness, contrast, hue, and salt-and-pepper noise. Figure 2 shows the same documents as Figure 1, but with applied image processing techniques.

The next idea was to use online templates for documents. The same information can be written a single time to produce a set of document images with different templates in this way. The combination of the above techniques increased the dataset size approximately four times.
The next issue was the high variance of data distribution. Document images could be computer-generated, scanned, or even photos. The biggest challenge was the photos of documents due to the presence of background, variability of document orientation, document distortions, etc. It is easier to deal with different documents if all of them are presented in the same format. Thus, it is important to identify photos among the provided document images. The set of image pre-processing techniques used is described shortly here. The classifier algorithm was trained to differentiate between proper images (computer-generated, scanned, vertically aligned) and photos (with background, distorted, rotated, etc.). After identifying photos in a document image stream, the background removal algorithm is applied to them. The result of this algorithm is the document image with background pixels turning black. This is done to emphasize the visual contrast between the edges of the document and the background. Then, the contour detection algorithm is applied to the document image to detect edges. This is performed to locate corner points of the document. Then, a set of affine transformations is applied to the located document image to vertically align it. Figure 3 shows the results of image pre-processing techniques on a photo.

Solution
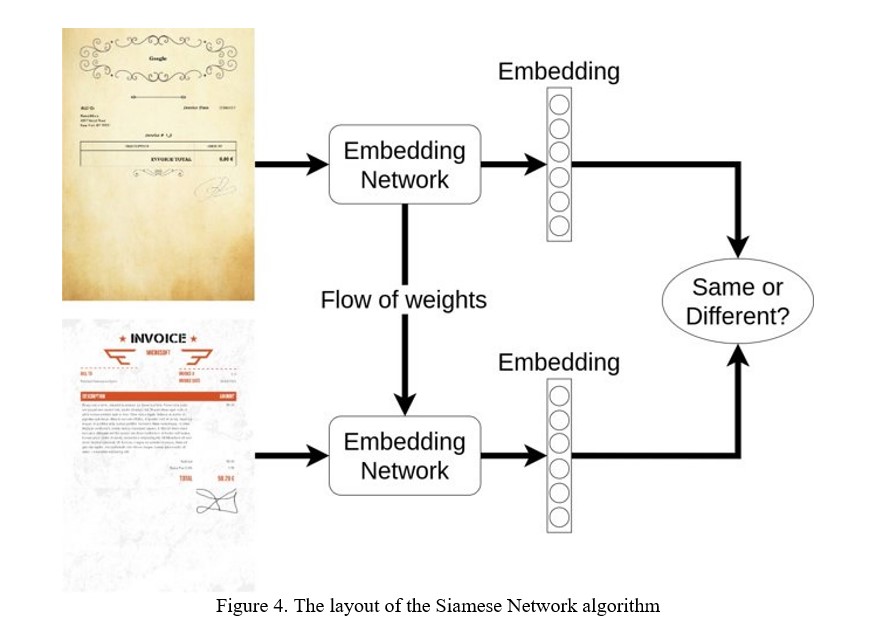
Finally, the properly formatted dataset of decent size is ready to be used for the machine learning algorithm. The set of document images provided by the user can consist of unique document types that are not present in the dataset. The algorithm should work even for document images it has never seen before, and also suggest if a new document type needs to be defined. The machine learning algorithm we used for solving this problem is known as the Siamese Network. The Siamese Network takes a pair of document images, converts each of them into an embedding vector (a list of floating-point values representing the document image), and checks if the vectors are close to each other or not. Figure 4 shows the Siamese Network model’s process. The distance between vectors can be measured by many techniques. The well-known Euclidean distance can be used to check if the vectors have a small distance or not. The machine learning model that is trained with this algorithm learns to encode the document images into embedding vectors. Then, it can generalize this encoding procedure to the document images it has never seen before. A threshold value is defined as a floating-point value to identify if the document images are similar to each other or not. If some document image is different from every document type, then a new document type can be suggested. Thus, the Siamese Network architecture solves the document type recognition problem with a variable set of document types. Next, this post focuses on the deployment of our solutions and integration of a continuous learning approach to the described problem.